Table of contents
Introduction
The yacsloader module provides several software elements :
- a C++ class that can be used to load a calculation schema in memory by reading and parsing a XML file describing it (see Programming with the yacs loader class).
- an executable named driver that can be used to load and execute (see Using the yacs driver) a calculation schema given as a XML file (see Writing a XML file).
Using the yacs driver
The driver program is a program that loads a schema file and executes it until its end. It is possible to display the schema state during the execution by specifying the –display option. An exemple of use is:
Internally, it uses the loader class, the Salome runtime, the standard executor with all is necessary to catch exceptions.
Writing a XML file
To write a XML file describing a calculation schema, you need to define several objects that are listed here :
- the calculation schema
- data types
- elementary calculation nodes
- connections between nodes
- initialization parameters
- composed calculation nodes
Defining calculation schema
To define a calculation schema, simply open a proc tag
All following definitions must be put between these tags.
Defining data types
A calculation schema is composed of interconnected calculation nodes. These nodes exchange data through data ports (in and out). The first thing you need to do is to define all types that can be exchanged in the schema.
Some types are already defined by the runtime you use. For example, the Salome runtime defines : int, double, string and bool types. It can also define all types used by the declared components. At the moment, the Salome runtime knows nothing about the types used by the declared components so it is mandatory to define all data types except the four basic ones.
It is possible to define three kind of types : basic, sequence and objref.
A basic type is an atomic one so it can only be int, double, string and bool. They are already defined so what can be defined is only alias to these types.
A definition of an alias to the double data type :
A sequence type is a constructed type that is built on already existing types. A sequence type defines a list of elements. The definition gives the name of the type and the type of the elements of the sequence.
To define a sequence of double type, add :
All attributes in the sequence tag are mandatory.
You can then define a sequence of sequence by :
An objref data type is an equivalent of a class in object languages. Salome components use objects which have types such as Mesh, Field, ... All these types can be related by inheritance relations.
Defining a base objref :
Defining a derived objref from mesh :
It is possible to derive an objref from multiple base objref and objref names can use name spaces. Just use a / as separator.
It is useful for Salome components because objref must be mapped to CORBA types which can use name spaces.
Finally, it is possible to define a sequence of objref :
RESTRICTION : struct type is not supported
Defining elementary calculation nodes
The next step is to define calculation nodes : service nodes or inline nodes.
There are three kinds of inline nodes : script inline node, function inline node and clone inline node, and three kinds of service nodes : component service node, reference service node and node service node.
The definition of all these nodes is described below.
- Script inline node
This kind of node corresponds to the execution of a python script with input and output parameters. Input and output parameters are passed to the script through data ports. A very simple example of an script inline node is :
The inline node has a mandatory name as all kind of nodes. The script tag indicates that it is a script inline node. The python script appears in as much lines as necessary between code tags in the script section. If your script contains a lot of "<" or "&" characters - as program code often does - the XML element can be defined as a CDATA section. A CDATA section starts with "<![CDATA[" and ends with "]]>":
In the example above the script calculates p1 that is an output parameter. An output data port must then be defined. A output data port is defined in an outport tag with two mandatory attributes : name and type that references an already defined data type. To define an input data port use the inport tag in place of outport.
Example of an inline node with input and output arguments :
Now the calculation node receives p1 as an input argument adds 10 to it and sends it as an output argument.
- Function inline node
This kind of node corresponds to the execution of a python function with input and output parameters. Input and output parameters are passed to the script through data ports. The main difference with the script node is the execution part. The definition of input and output ports is unchanged. In the execution part use the function tag in place of the script tag and add a name (mandatory) which must be the same as that of the function.
An example of an function inline node is :
- Clone inline node
This node is a convenience node to avoid repeating an inline definion. It allows to create an inline calculation by using the definition of another inline node. Such a kind of node is defined in a node tag with two mandatory attributes : name (the node name) and type that indicates the name of the already existing inline node to use for the definition. Example :
- Reference service node
A service node corresponds to the execution of a service available from a calculation server. It can thought of as the execution of an object method. A service node is defined in a service tag in place of the inline tag for the inline node.
In a reference service node the calculation server is known by its address (which is a string meaningful for the runtime) and is supposed to exists before executing the calculation schema. The service is known by its name. Then the service has input and output arguments that are passed through ports in the same way as the inline nodes. The server address is defined as a string in a ref tag and the service name is defined in a method tag. Example :
The service node node4 is a reference service node because it has a ref section. The address of the calculation server to use is a CORBA address that must be meaningful to the runtime. The service to use is the CORBA operation echoDouble that just gets the input and returns it.
- Component service node
This kind of node is similar to the previous one but the server does not exist before the beginning of the execution. It's the runtime that is in charge of loading the calculation server or component for Salome platform. Instead of defining the address of the server we give the name of the component that will be loaded through the runtime by the platform. This name is given in a component tag in place of the ref tag. Example :
- Node service node
It's a special node that gives the possibility to create a service node that calls a service of an already loaded component. To define such a node you need to indicate the name of an already existing component service node in a node tag in place of the previous component tag.
A short example is better than a long speech :
Here, node5 is a service node that executes the echoString service of the component that has been loaded by the component service node node4.
Defining connections between nodes
After having defined all the calculation nodes needed, it is necessary to connect them to define the order of execution (control flow) and the exchanges of data (data flow).
- Control flow
The order of execution is defined by means of control links between nodes. These links are defined in a control tag with subtags fromnode and tonode which give the names of precedent node and following node. Example of control link :
This control link indicates that execution of node2 must be after complete execution of node1.
- Data flow
Exchange of data between nodes is defined by means of data links between output ports and input ports. These links are defined in a datalink tag with subtags fromnode, tonode, fromport and toport. The output port is specified with the node name and the output port name. It's similar for the input port.
Example of data link :
This data link indicates that the output argument p1 of node node1 will be sent to node node2 and used as input argument p1. By default, with this datalink definition, a control link is automatically defined between node1 and node2, to ensure a complete execution of node1 before node2 starts. Sometimes, this control link must not be created, for instance with loops (see below). With most simple cases, yacs loader is able to decide to create or not the control link. It is always possible to ask explicitely a data link without control link:
So, it is equivalent to write:
Or:
Control links may be defined implicitely several times without problem.
Defining initialization parameters
It is possible to initialize directly input ports with constants. This is done with a definition put in a parameter tag with subtags tonode, toport and value. tonode is the name of the node and toport the name of the port to initialize. value gives the constant to use to initialize the port. This constant is given in XML-RPC coding convention (http://www.xmlrpc.com/).
Example of parameter initialization :
This parameter initialization indicates that the input argument p1 of node1 is initialized with a string constant ("coucou").
Putting all this together
Now that we are able to define data types, calculation nodes and links, we can define a complete calculation schema with interconnected calculation.
We have put together 2 inline nodes and one reference service node with nodes node2 and node4 that will be concurrently executed as can be seen on the control flow diagram below.
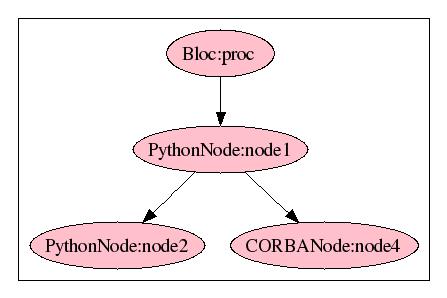
Defining composed calculation nodes
The next step is to define composed nodes either to modularize the calculation schema or to introduce control nodes like loop or switch.
- Using block to modularize the schema
All the previously defined elements (except the data types) can be put in block nodes. It is easy : create a bloc tag with an attribute name that contains all the definitions and you have a composed node that is a block.
Example of block :
This block can now be linked with other nodes of any kind in the same way as elementary nodes. The rules are : it is not possible to set control links that cross the boundary of the block. On the other end, it is possible to set data links that cross this boundary either on input or on output.
- Defining a For Loop
If you want to execute a calculation n times, you can use a ForLoop node to define this kind of computation. A for loop is defined in a forloop tag that has 2 attributes : name and nsteps. name is as always the name of the node and nsteps is the number of steps of the loop. The for loop must contain one and only one node that can be an elementary calculation node or a composed node. It is possible to have a for loop in a for loop, for example. If you want to put more than one calculation node in a for loop, use a block.
Example :
The rules are the same as for the block node. But inside loops, to be able to perform iterative computation, it is allowed to link an output port of an internal node with an input port of a previous node in control flow. The only limitation is that you have to put the node and the data link in a block node as links can't be defined in a forloop section.
Here is an example :
Last point : it is possible to link the nsteps entry of the for loop with an output port that produces integer data. The input port of the loop has the same name as the attribute (nsteps).
- Defining a While Loop
This kind of loop is mainly similar to the for loop. The only difference is that the loop executes as long as a condition is true. A while loop is defined in a whileloop tag and has only one attribute : name as usual. The condition value is set through an input port (which name is condition) that accepts boolean value.
Example of a while loop:
It is here again possible to define composed node of any kind as internal node to define loops in loops.
- Defining a Switch Loop
A switch node is equivalent to a switch C. It has an input port (which name is select) that accepts integer data. According to the value in the select port one or another case node is selected for execution. Each case is defined in a case tag with one attribute id that must be an integer or default. If no case is defined for the select value the switch node uses the default case. A case can contain one and only one internal node.
A minimal but almost complete example :
Programming with the yacs loader class
To use the yacs loader class, first create a specific runtime (here a Salome one).
Then you can create an instance of the yacsloader class and call the load method with the name of the XML file as argument.
The call to the method will return a calculation schema (instance of the Proc class).
You can then dump to a file a graphviz diagram by calling the writeDot method on the schema.
You can display the diagram with: dot -Tpng proc.dot |display.
And then execute the schema with an Executor.