L’itération¶
La définition d’une itération se fait par la donnée des informations suivantes :
- L’itération précédente
- Le nom du maillage résultat
- L’hypothèse utilisée
- Eventuellement, le fichier du champ d’indicateurs d’erreur
Le nom de l’itération¶
Un nom d’iteration est proposé automatiquement : Iter_1, Iter_2, etc. Ce nom peut être modifié. Il ne doit pas avoir été utilisé pour une itération précédente.
L’itération précédente¶
L’itération précédente est choisie dans l’arbre d’étude. Le nom du maillage correspondant sera affiché.
Le nom du maillage résultat¶
L’itération en cours de création produira un maillage. Ce maillage sera connu sous un nom. Ce nom est fourni en le tapant dans la zone de texte. Par défaut, on propose un nom identique à celui de l’itération précédente.
Le champ¶
Pour créer ou utiliser une hypothèse d’adaptation basée sur un champ exprimé sur le maillage, on doit fournir le fichier où se trouve le champ. C’est également le cas si on veut interpoler des champs du maillage n au maillage n+1. Ce fichier est au format MED. Classiquement, il aura été produit par le logiciel de calcul avec lequel on travaille. Le nom du fichier peut être fourni, soit en tapant le nom dans la zone de texte, soit en activant la fonction de recherche.
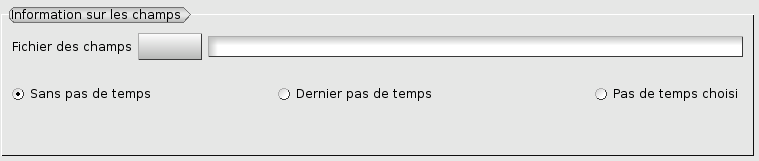
Dans le cas où des pas de temps ont été définis, une solution simple consiste à traiter les champs au dernier pas de temps enregistré dans le fichier. Si on veut définir un autre pas de temps, on coche le bouton “Pas de temps choisi”. Les valeurs de ‘Pas de temps’ et de ‘Numéro d’ordre’ sont celles correspondant à la convention MED (time step / rank). Ces valeurs dépendent de la logique qui a été retenue par le logiciel qui a écrit le fichier. Souvent ces deux valeurs sont identiques mais il arrive que l’on disjoigne les pas de temps et les intervalles d’archivage.

L’hypothèse utilisée¶
L’itération en cours pilotera l’adaptation par HOMARD selon un scénario défini dans une hypothèse. Celle-ci est choisie dans la liste des hypothèses existantes.
Au démarrage, il faut créer une première hypothèse par activation du bouton “Nouveau” (voir L’hypothèse) :

Ensuite, si une hypothèse précédemment définie convient, il suffit de la sélectionner dans la liste proposée. Sinon, il faut créer une nouvelle hypothèse par activation du bouton “Nouveau”, puis la sélectionner dans la liste proposée :

Note
Si on envisage une adaptation selon les valeurs d’un champ sur le maillage, il faut avoir renseigné les informations sur ce champ avant de créer une nouvelle hypothèse.
L’arbre d’étude¶
A l’issue de cette création d’itération, l’arbre d’études a été enrichi. On y trouve l’itération initiale, identifiée par le nom du maillage qui a été lu dans le fichier fourni, l’itération courante, identifiée par son nom. On trouve aussi l’hypothèse qui lui est attachée. L’icône en regard de l’itération permet de différencier les itérations calculées ou non.
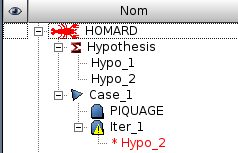
Quand plusieurs itérations s’enchaînent, leur hypothèse est visible dans l’arbre d’étude. On remarquera dans la figure ci-après que deux itérations peuvent partager la même hypothèse.

Méthodes python correspondantes¶
Consulter L’itération